

嗨伙伴们,今天是干货分享哦,可千万不要错过。今天小蝌蚪教大家使用phthon时学会巧妙借用代理ip来更好地完成任务。Python爬虫在数据采集这样的大规模数据抓取过程中,会遇到各种各样的阻碍和困境,一般这个时候,我们可以通过一个手段来解决,那就是代理ip,通过代理ip来解决这样的棘手的问题。那具体是如何做的的呢,让我们接着往下看。
让我们先了解一下为什么说咱们要用爬虫代理ip呢,那是因为很多网站为了防止有人过度爬取数据,对自身资源造成损害,于是他们都纷纷设置了对同一IP的访问频次限制。如果持续使用同一个IP来频繁地进行访问,那么极有可能被网站封禁 这个ip 地址,从而导致数据采集工作被迫中断。这个时候如果我们借助代理IP来操作,那我们就能够不断地切换IP,就能让我们的ip地址在网络世界中隐身,这样就能够有效规避被封禁的风险。
我们通过运用多个代理IP同步进行爬取操作,可以显著提升数据采集的速度与效率。我们来给大家打个比方,这就好像是一支训练有素的军队,一声令下,各个小分队就同时出击,它们迅速占领目标区域,将宝贵的数据资源收入囊中,出色地完成任务。
那我们怎么才能挑选到最合适的爬虫代理ip呢?最先要注意的就是,我们要选择稳定可靠的代理IP服务服务商。不稳定的代理IP就像一颗不定时炸弹,随时可能频繁掉线,严重影响爬取进度。只有可靠的代理服务商才能提供高质量稳定的代理IP,才能为数据采集工作提供坚实的保障,确保整个过程顺利进行,否则进行到一半,出现问题不就前功尽弃了嘛。接下来要注意的就是代理IP的响应速度一定要快,这个直接影响到爬虫的效率。我们一定要挑选速度快的代理IP,这样就能够减少等待的时间,这就好比给爬虫安装上了强劲的引擎,让它在数据的赛道上飞速驰骋,能够大幅提高爬取速度。另外我们还可以用高匿名度的代理IP,因为高匿名的代理ip可以更好地保护隐私,避免IP被目标网站轻易识别。就像一位神秘的特工,隐藏在黑暗中,悄然完成任务而不留下任何痕迹。
当然我们还要依据自身需求与预算,挑选合适的代理IP服务。在这里需要提醒大家的是,一些免费的代理IP往往存在不稳定、不安全等诸多问题。在选择时,大家一定要综合考虑价格与质量,找到性价比最高的解决方案。
讲完了理论,小蝌蚪来给大家上点实战课,我们来具体看看如何在Python爬虫中运用代理IP。
我们可以借助requests库设置代理IP,requests是Python中常用的HTTP库,能够便捷地设置代理IP。下面小蝌蚪给大家看一下示例代码:
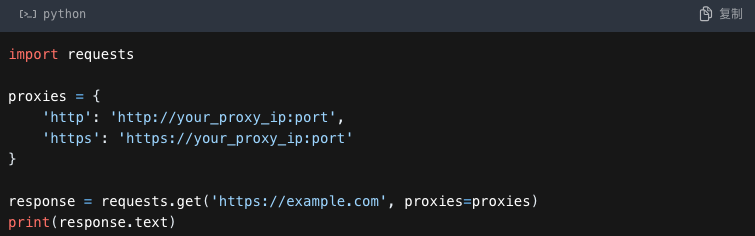
在爬虫代码中可通过“meta”参数传递代理IP:

这里需要注意下,在启用代理IP之前,最好先进行测试,来确保代理IP可以正常使用并且是稳定的,只有经过严格测试的代理IP才能在战场上发挥出最大的作用。
为防止被目标网站识破,我们建议大家要定期更换代理IP,从而确保数据采集工作的顺利进行。
那么在结束前,小蝌蚪来总结一下,在Python爬虫中如果我们巧妙地运用爬虫代理IP,能够帮助我们突破IP限制,提升爬取效率,同时守护隐私安全。不过要注意的是,在使用过程中,大家一定要谨慎地选择合适的代理IP服务商,并严格遵守法律法规,确保自身行为的合法合规性。只有这样,我们才能在数据的海洋中畅游无阻,开启高效的数据采集之旅。
那今天的干货就分享到这啦,大家还想知道什么可以留言哦。